
머신러닝이란?
l 머신러닝이란?
l 시대에 따른 머신러닝의 변화
l 머신러닝과 딥러닝의 차이점
l 현대사회 적용 사례
l 컴퓨터 사이언스와 머신러닝의 차이점
머신러닝이 무엇인지, 시대에 따른 머신러닝의 변화, 머신러닝과 딥러닝의 학습 방식과 차이점에 대하여 각각 예를 들어 이해하기 쉽게 설명하고 있습니다. 또한 현대 사회에서 적용되어 사용되고 있는 사례와 머신러닝에서 사용되고 있는 알고리즘의 종류, 컴퓨터 사이언스와 머신러닝의 차이점을 이해하기 쉽게 설명하고 있습니다.
학습 목표

머신 러닝 : 기계가 "데이터"를 학습한다
1) 데이터가 중요해야 한다.
2) 데이터를 분석할 때 수학적 방법을 사용하지만, 수학에 대한 기초 지식을 동반하여 소프트웨어나 툴로 사용가능하다.
3) 수학적 방법 = 문제를 해결하는 방법 = 알고리즘
복잡한 기능을 구현하기 위해 머신러닝에서 딥 러닝을 발견함
머신러닝의 종류 중 하나가 딥 러닝
사람의 뇌 구조를 모방하여 만들어낸 것이 딥 러닝
신경망 이론 :
인공 신경을 연결하여 신경망을 만듦
그리고 신경망에 데이터를 흘려보내 사람이 학습을 하는 것처럼 신경망도 데이터를 사람처럼 학습하게 한다.

기계가 학습되어야 한다.
컴퓨터의 언어(데이터)로 학습을 시킨다
각각의 데이터나 문제의 종류에 따라 알고리즘을 수행한다
이 전체 과정을 사람이 하는 것이다.
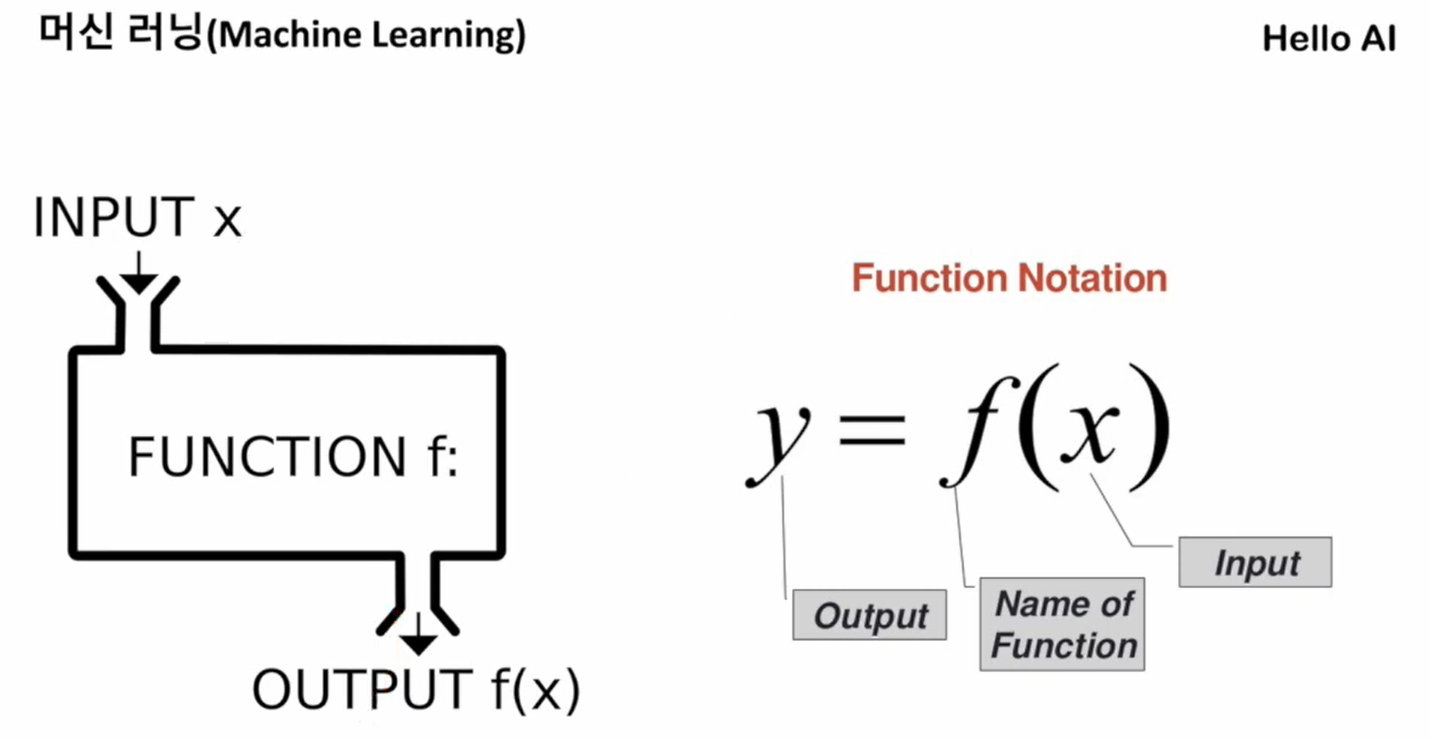

a와 b를 넣으면 a+b가 나오도록, 덧셈의 개념을 알고 그것을 코딩하는 것은 개발자가 하는 것이다

머신러닝은 이러한 함수들=여러 개의 데이터를 기반으로 해서 가운데 과정을 컴퓨터가 이해하기 시작하고 스스로 답을 내는 것을 말한다.

머신 러닝 알고리즘
l 머신러닝 알고리즘이란?
l 지도 학습의 개념
l 비지도 학습의 개념
l 강화 학습의 개념
다음과 같으며,
지도 학습, 비지도 학습, 강화 학습의 머신러닝 알고리즘의 개념 및 다양한 알고리즘을 이해하기 쉽게 설명하고 있습니다. 또한 지도 학습의 분류, 회귀와 비지도 학습의 이상 감지, 군집 마지막으로 강화 학습을 각 학습에 대한 학습방법 및 서로의 차이점과 알고리즘들을 각각 예를 들어 이해하기 쉽게 설명하고 있습니다.
알고리즘 : 어떤 문제를 풀기 위해 만들어놓은 학습 방법들

머신러닝의 종류들
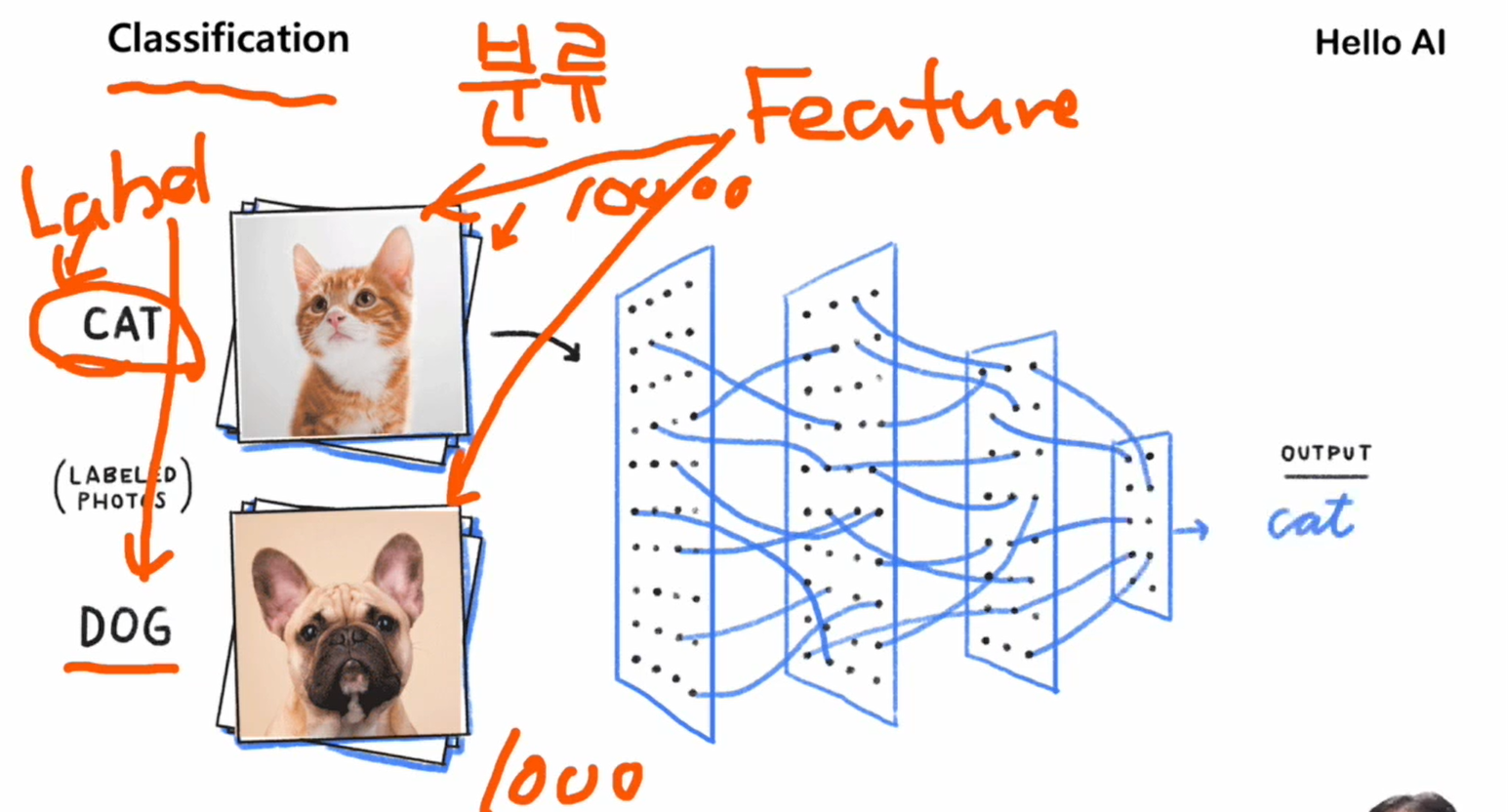
1)지도 학습 : Regression, Classification

무언가를 가르쳐주고 학습시킨 뒤에 정답을 맞추게 한다.
문제(피쳐)와 정답(레이블)을 제공해줌 -> 하나의 기초 문제
예측/추정/분류를 할 수 있음
Clssificaion (분류)
Regressin (회귀)
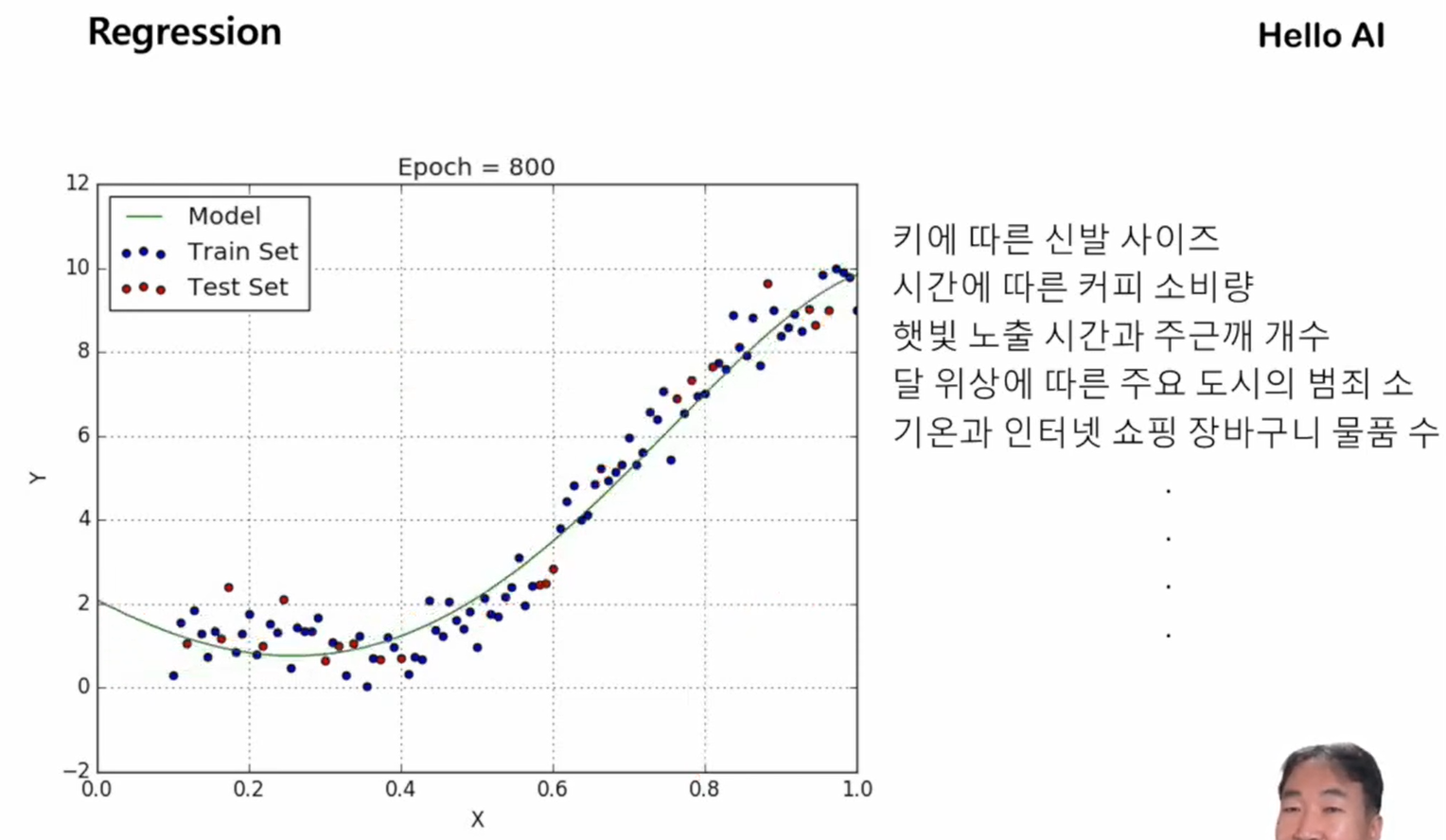
어떤 상황에 맞춰 값을 예측하는 것
키에 따른 신발 사이즈의 데이터를 전부 찍어본 뒤,
평균을 통과하는 선을 긋는다 -> 값 예측 위해 데이터를 모으고 라인을 긋고 라인을 기점으로 예측해본다
2) 비지도 학습

문제만 제공이 되고, 문제 안에서 패턴이나 구조를 확인해야 한다
Anomaly (이상 징후 감지)
원래의 평소 값에서 임계치를 넘어가는 값이 있거나 평소와 다른 패턴을 보이면 이상감지를 하겠다

Clustering (군집)
레이블이 없는 데이터를 막 쌓아놓는다
알고리즘에 의해 데이터들의 유형이나 패턴을 보고 선을 그은다음에 예쁘게 작은 집합으로 만들어놓는다
분류와 유사할 수 있지만,
분류는 항상 레이블 값이 존재한다.
하지만 군집은 레이블 값이 없이 그냥 전부 쌓여있다. (레이블의 유무 차이)

Reinforcement Learning (강화 학습)

보상에는 인과 관계가 중요하다.
인과 관계가 잘못 설정된다면 안된다.
잘 할때마다 리워드를 높게 주면, AI는 높은 점수를 위해 학습을 한다

데이터란
l 머신러닝의 단계
l 데이터란?
l 데이터의 요소
l 데이터 획득 방법
다음과 같으며,
머신러닝을 시작할 때의 단계에 대해 먼저 설명하고, 데이터란 무엇인지 데이터의 개념을 이해하기 쉽게 설명하고 있습니다. 또한 데이터의 중요성, 데이터의 필요성, 데이터를 어떻게 잘 준비해야 하는지 알기 쉽게 설명하고, 데이터의 요소 및 데이터를 어디서 어떤식으로 획득할 수 있는지 설명하고 있습니다.
학습 목표
머신러닝을 위해 데이터들을 모으고 어떻게 필요한 데이터만 골라내는지 알아보자
머신러닝의 단계

1) 해당되는 영역에 최적화되어있는 기술이 필요한다. (물류를 예측하고 싶으면 물류 전문가가 필요하다. 해당 도메인에 대한 전문 지식이 더 중요하다)
2) 해당되는 비즈니스의 문제가 무엇인지 정확하게 파악하는 것이 중요하다.
3) 문제를 해결하는 데에 있어서 정말 올바른 데이터인지, 전체 데이터가 아니라 컬럼만을 사용할 것, 데이터를 해결하기에 적합한 알고리즘인지를 파악해야 한다.
4) 위 과정을 다 거쳐야 머신러닝을 도입한다.
데이터란?

1) 회귀 알고리즘을 적용하기 딱 좋은 데이터!
연봉 : Feature
근속 연수 : Label = Target(어떤 값을 예측하기 위한 값이니까)
근속 연수를 물으면 연봉이 어떻게 될까?
예측을 할 때 Feature를 주면 Label을 준다

2) 타이타닉호 데이터
산 자 / 죽은 자를 구분하기 때문에
Classfication 알고리즘을 적용할 수 있다.
이름과 티켓 넘버, 키, 출항지는 학습에 전혀 중요하지 않기 때문에 Feature에 선정되지 못한다.
관련 여부 데이터만을 뽑아 Label을 만든다

데이터는 크게 두 분야가 있다. -> X / Y
데이터를 통째로 사용하는 것이 아니라 잘라서 사용하는데,
데이터를 학습시키고 나서 학습이 잘 되었는지 확인하기 위해
X_train으로 학습을 시키고(Train data set) / X_test로 학습이 잘되었는지 확인한다. (Test data set)
Y쪽도 동일하다.
가끔은 3가지로 학습/검증/테스트로 나누기도 한다.

Random Split
학습을 할 때는 True/False가 섞여있는 데이터로 학습했다가,
테스트를 할 때는 False만 있는 데이터로 학습하면 안되니까 데이터를 잘 섞어야한다.
데이터를 구할 수 있는 곳
1) 캐글

2) 국가 통계 포털



오렌지란?
l 오렌지란?
l 오렌지 데이터 마이닝의 장점
l 오렌지 데이터 마이닝 설치
l 오렌지 데이터 마이닝 주요기능
l 오렌지 데이터 마이닝 사용방법
데이터 마이닝 도구에 대해 먼저 설명하고, 오렌지 데이터 마이닝 도구의 장점을 이해하기 쉽게 설명하고 있습니다. 그리고 오렌지의 설치 및 아나콘다에 대해서 설명합니다. 또한 오렌지의 주요기능들과 주요 알고리즘을 알기 쉽게 설명하고, 오렌지 데이터 마이닝 도구의 사용방법을 실습과 함께 설명하고 있습니다.



QT는 UI를 만들 때 사용하는 공개 소프트웨어 -> 윈도우/맥 등 크로스플랫폼 지원


회귀 분석이란?
l 회귀분석(Regression)이란?
l 오렌지에서 데이터 불러오는 방법
l 데이터의 확인, 분포, 예측
회귀분석(Regression)에 대해 이해하기 쉽게 설명하고, 오렌지 데이터 마이닝 도구에서 데이터를 불러오는 방법 세 가지 파일 입력, 샘플 데이터 사용, SQL 테이블 입력에 대해 설명하고 있습니다. 또한 CSV 형식의 파일을 만들어 산점도를 활용한 데이터 분포 확인, 회귀분석(Regression)을 통한 데이터 예측을 실습과 함께 알기 쉽게 설명하고 있습니다.

엑셀 파일을 Comma Separate Valuation(CSV)로 저장

데이터 분포가 어떻게 되어있는지 보기 위해 Scatter Plot 사용
데이터를 눈으로 보면서 어떻게 활용할 것인지 예측해보기 위해 위와 같은 일련의 과정을 마쳤다.
Model에 있는 것들이 전부 알고리즘!
Evaluate로 평가하기


선형 회귀 알고리즘을 쓰니 잘 예측한다
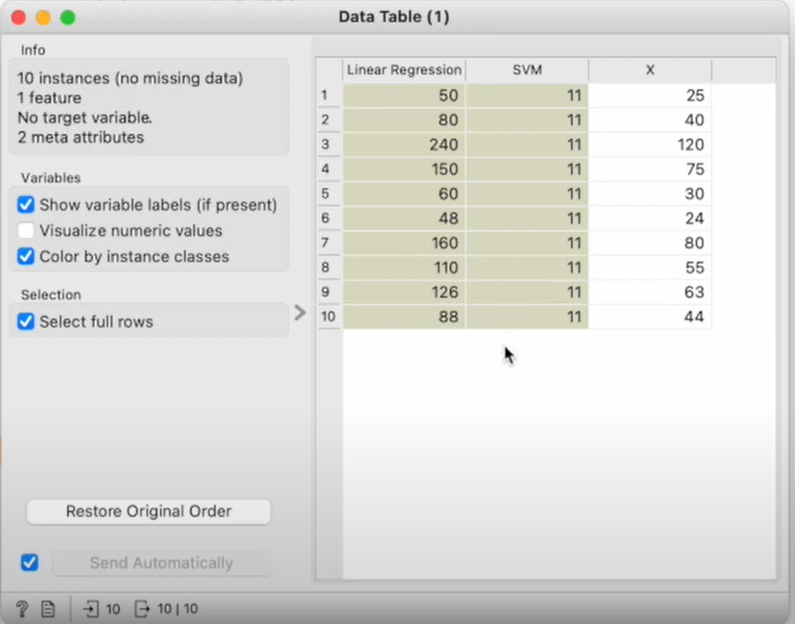
SVM 알고리즘을 넣어봤더니 예측결과가 영 꽝이다..
알고리즘을 잘 선택해야한다!
회귀분석 모델의 평가
l 회귀분석 모델 평가 방법
l 회귀분석 모델 평가 해석
보스턴 집값 샘플 데이터의 칼럼들을 알기 쉽게 해석하고, 실습을 진행합니다. 이 실습 과정 중 보스턴 집값 샘플 데이터에 대한 각각의 알고리즘을 평가하고 랜덤 샘플링을 하는 이유를 이해하기 쉽게 설명합니다. 또한 이 평가 점수를 해석하는 방법을 소개해 주고 MSE, RMSE, MAE, R²에 대하여 알기 쉽게 설명하고 있습니다.

Test and Score : 주어진 점수에 대해 테스트하고 점수를 매기는 것
Predictions : 실제 데이터를 가지고 예측해보는 것

평가 방법
1) MAE : 절대 평균 오차
데이터들(점)이 선에서 떨어진 정도
2) RMSE : 오차에다가 제곱을 한다
오차가 너무 작아서 보이지 않을 까봐, 제곱을 해서 크게 보이게 한다
결과 수치가 너무 작을 때 제곱을 해서 본다
제곱을 할 때 에러가 날 수도 있으니 루트를 씌운다.
3) MSE : 예측 값과 실체 값의 차이의 제곱을 평균낸 것
4) R2 : 결정 계수
결과를 나눠서 1에 가까울 수록 좋은 것
1~3까지 작을 수록 좋고,
4는 1에 가까울 수록 좋다

분류
l 분류(Classification)란?
l 단일 분류와 다중 분류
l 데이터의 확인, 분포, 예측
다음과 같으며,
분류(Classification)에 대해 이해하기 쉽게 설명하고, 단일 분류와 다중 분류에 대한 설명을 예시와 함께 알기 쉽게 설명합니다. 또한 분류 알고리즘을 쓸 데이터의 형식을 CSV 파일을 만들어 산점도를 활용한 데이터 분포 확인, 분류(Classification)을 통한 데이터 예측을 실습과 함께 알기 쉽게 설명하고 있습니다.
둘 중 하나, 넷 중 하나 등 여러 개중의 하나로 나누는 것이 분류!
회귀는 선을 긋고 X,Y중에 값을 예측하는 것

Logistic Regression
라인을 기점으로 A,B를 나누는데, 이것이 Linear Regression과 비슷해서 Regression 이름이 붙었지만
가장 대표적인 Classfication 알고리즘 중 하나이다.

데이터 테이블로 예측한 결과 보기

Tree 알고리즘
어떤 데이터가 있다면, 경우의 수만큼 계속해서 질문을 던진다.
그렇게 계속 질문을 던진 뒤 계층별로 접근하는 것을 말한다.
시각화 기법
-Tree Viewer : 트리 계열 알고리즘이 어떤 과정을 통해 이런 결과를 냈는지 보여줌

-Distributions : 데이터를 막대 그래프로 보여줘서 어디쪽에 더 많이 분포되어있는가를 보여줌

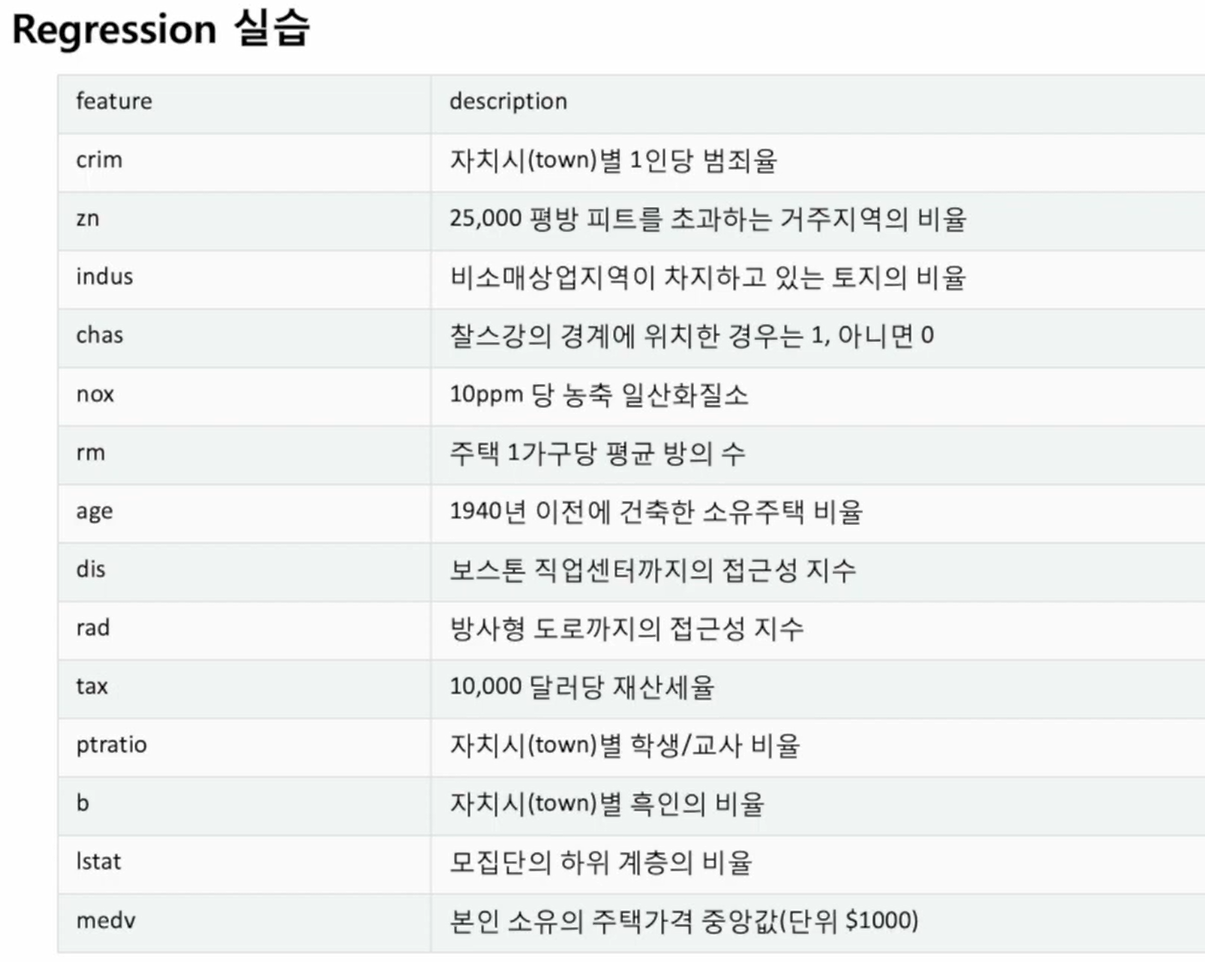
-Box Plot : 데이터가 어딘가에 모여있으면 "박스권"이라고 한다.
합격자 에이 그룹, 불합격자 비 그룹
분류 모델의 평가
l 분류 모델 평가 방법
l 분류 모델 평가 해석
붓꽃 샘플 데이터의 칼럼들을 알기 쉽게 해석하고, 실습을 진행합니다. 이 실습 과정 중 산점도와 박스 플롯을 이용하여 데이터의 분류 기준에 대해 설명하고, 붓꽃 샘플 데이터에 대한 각각의 알고리즘을 평가하고 설명합니다. 또한 이 평가 점수를 해석하는 방법을 소개 해주고 ROC, Precision, Recall, Accuracy, AUC 등 평가 지표에 대하여 알기 쉽게 설명하고 있습니다.

Instance : 각 한 줄 한 줄의 데이터를 뜻함
Feature : 구별 기준 - 4개
numeric : 수치 타입
categorical : 구별자 역할
데이터를 눈으로 살펴봐야 한다.
어떤 데이터가, 어떻게 분포되어있는지 Visualize로 확인

분류의 가장 대표적인 알고리즘 Logistic Regression
그리고 Tree 계열의 Tree 알고리즘

ROC란, 전체 면적이 넓을 수록 정확도가 높다

AUC가 ROC 그래프 아래의 면적을 말한다.

Tree 알고리즘이, 더 복잡하게 진화한 것을 Random Forest 알고리즘
Neural Network 신경망 개수와 반복 횟수를 증가
Adaboost 등등.....
테스트를 다 해봤으니 정확도(CA)가 가장 높은 Logistic Regression 알고리즘이 적합하다
하나하나 정확도 높은 것을 찾아나가는 것이므로 머신러닝은 귀납적 방법이다.
Logistic Regression 일반화 모델 :
1)Lasso
2)Ridge
정리

군집
l 비지도 학습 이란?
l 군집(Clustering)이란?
l 데이터의 확인, 분포, 예측
비지도 학습에 대한 개념을 이해하기 쉽게 설명하고, 비지도 학습 중 군집(Clustering)에 대하여 설명합니다. 그리고 오렌지안의 이미지 분석 툴을 설치하여 군집(Clustering) 분석을 진행합니다. 또한 컴퓨터의 이미지 해석 방법에 대해 알기 쉽게 설명하고, 군집(Clustering) 알고리즘을 통한 군집 형성을 실습과 함께 알기 쉽게 설명하고 있습니다.

데이터들이 각자 모인다 -> 군집 알고리즘
Options -> Add-ones 클릭 -> Image Analytics / (문제에 정답이 image learning라고 한다) 설치

Unsupervised에서 Distances를 선택
군집에서 데이터들 각각의 거리를 측정한다.
적당한 거리가 인식되면 군집을 형성한다.
Distance Matrix로 결과를 보면, 데이터들이 구별이 되어서 나오고 있다.

Hierarchical Clustering에 Image Viewr를 연결하면, 어떻게 분류되었는지 확인할 수 있다.
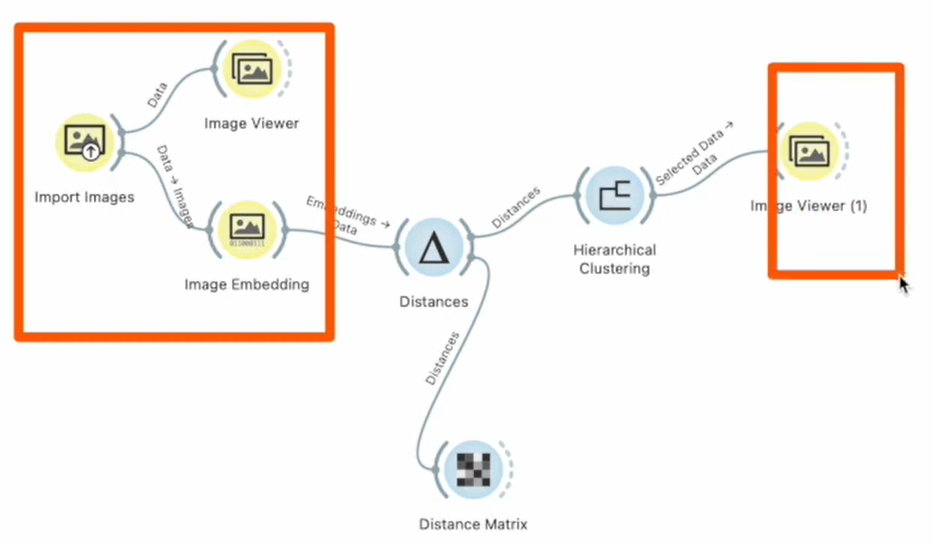
또한 Data Table도 연결하면 수치별로 볼 수 있음!

이미지를 파악하거나 분류하는 것을
Computer Vision이라고 한다.
Open Data
l 데이터 수집 방법
l 엑셀의 데이터 분석 기법
데이터를 어디에서 어떻게 수집하는지 알기 쉽게 설명하고 있습니다. 국가 통계 포털에서 사용자가 원하는 항목에 접속하여 데이터를 내려받는 과정을 설명하고 있습니다. 또한 케글에 올라와 있는 데이터들을 어디에서 가져와 사용할 수 있는지 설명하고, 다른 사람이 작업한 것들을 볼 수 있는 방법을 소개하고 있습니다. 그리고 이렇게 내려받은 데이터를 엑셀의 데이터 분석 기법을 통하여 간단한 상관관계 분석을 소개합니다.



인구 통계 데이터 추천합니다!
차트도 제공하니 잘 활용해보자
국내 카드별 사용 승인 실적 확인



오렌지나 다른 툴에서 열어 작업하기 전에,
엑셀 파일로 열어 데이터를 전처리한다.


Data analysis에서, Correlation을 사용해 (상관 계수) 각각의 항목들이 얼마나 상관이 있는지를 분석해본다


도매 및 소매업과 보건업은 0.84 -> 꽤 높은 관계를 보인다.
엑셀만 조금 잘 써도 데이터의 통계를 내는 등 여러가지 작업을 할 수 있다.
캐글 또한 데이터 분석의 성지이다.. 코드를 잘 해석할 수 있으면 실력이 상당히 향상할 것이다

Microsoft AI
l Microsoft AI 솔루션
l Microsoft AI의 철학
l Microsoft AI Portfolio
AI를 써야 하는 이유와 AI의 역사를 설명한 뒤 Microsoft의 AI 사용 역사에 대해 알기 쉽게 설명하고 있습니다. Microsoft AI 서비스의 Vision, Speech, Language, Knowledge 4가지에 대해서 소개하면서 클라우드 기반의 장점을 설명합니다. 또한 Microsoft AI Portfolio의 Agent, Applications, Services, Infrastructure 4가지를 동영상과 함께 서비스 구축의 장점을 설명하고 있습니다.
인공지능은 클라우드와 떼어놓을 수 없는 관계가 되었다
데이터가 빅 데이터가 되고, 데이터가 커지다보니 풀어야할 문제가 많아지고 빅 컴퓨팅이 필요해지고 컴퓨터 자원이 필요해졌다.
그래서 필요할 때 필요한 만큼 쓸 수 있는 컴퓨터 자원이 필요했다.
데이터가 들어오면 새로운 인사이클을 더 뽑아내고, 거기서 더 데이터를 뽑아내고, 인사이클을 뽑아내고 이러한 순환을 클라우드를 통해 가능하다.
봇 프레임워크 : 챗봇 만들 수 있음
AI에는 GPU가 쓰이지만 FPGA도 쓰이며 친환경적이다
'AI School' 카테고리의 다른 글
| AI-900_Computer Vision (0) | 2022.04.30 |
|---|---|
| AI-900_Introduction to AI (0) | 2022.04.27 |
| 220422_Docker와 Kubernetes (0) | 2022.04.22 |
| 220421_Azure 데이터베이스 (0) | 2022.04.21 |
| 220420_인증과 권한 (0) | 2022.04.20 |
