02 Machine Learning
이번 강의에서는 Machine Learning과 Machine Learning 방법 및 Azure Machine Learning 에 대해 설명합니다.
1.1 Machine Learning이란?
- 과거의 데이터에서 관련성을 찾아 예측 하는 모델을 만드는 것
- 인공지능을 사용하기 전 과거 통계에서는 과거의 데이터를 모두 사용했지만 머신 러닝에서는 과거의 데이터를 두개로 쪼갭니다. (Split data)
- Training Data - 학습 데이터를 통해 모델을 만듭니다.
- Validation Data - 나머지 데이터를 모델에 넣어서 예측이 잘 되는지 검증합니다.
- 데이터는 보통 7:3 또는 5:5로 랜덤하게 행으로 분할합니다.
1.2 Regression (회기 분석)
- 회기 분석은 함수 식에 값을 넣어서 미래를 예측하는 분석 방법입니다.


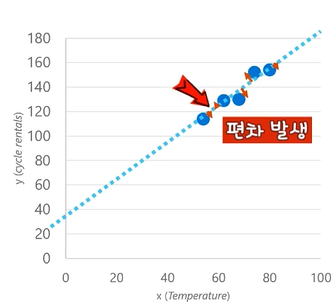
왼쪽 이미지의 온도 별 자전거 렌탈 댓수 데이터 값을 통하여 오른쪽 이미지의 그래프를 그릴 수 있습니다.
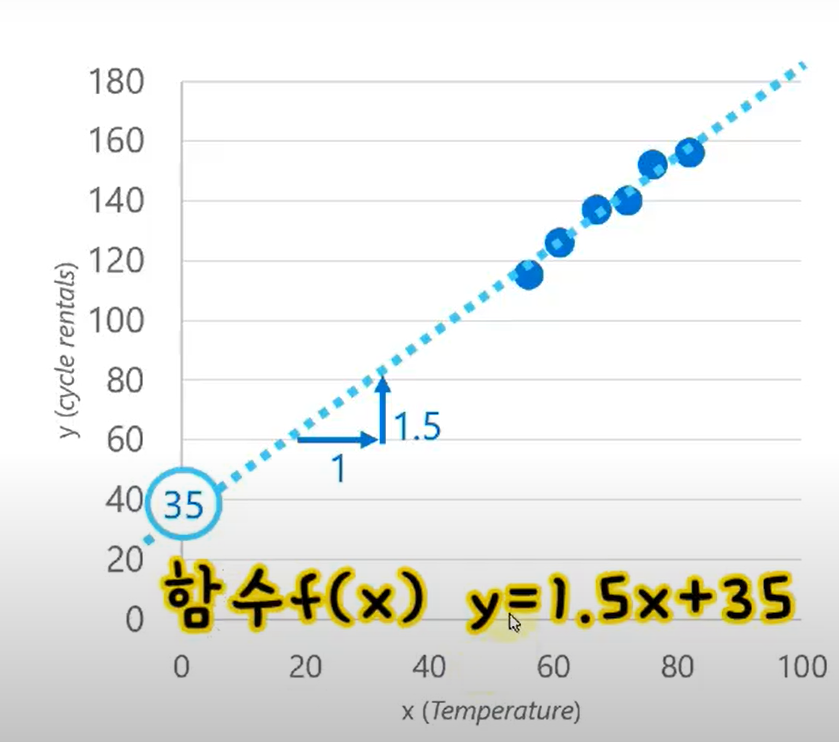
- 데이터들의 연장선을 통하여 기울기를 확인할 수 있습니다.

- 그래프의 기울기를 통해 y절편을 구하고 함수식으로 표현할 수 있습니다. 즉, 모델은 함수식입니다.
- 함수식에 x값인 온도를 넣으면 그래프에서 편차가 발생하게 됩니다.
이러한 편차를 줄이고 정확한 예측 모델을 찾는 것이 머신러닝의 핵심입니다.

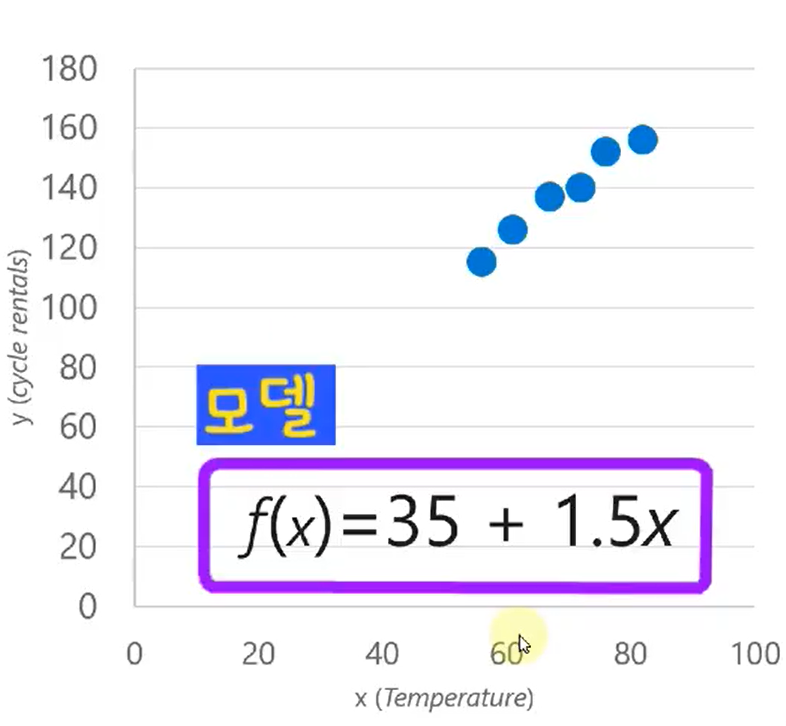
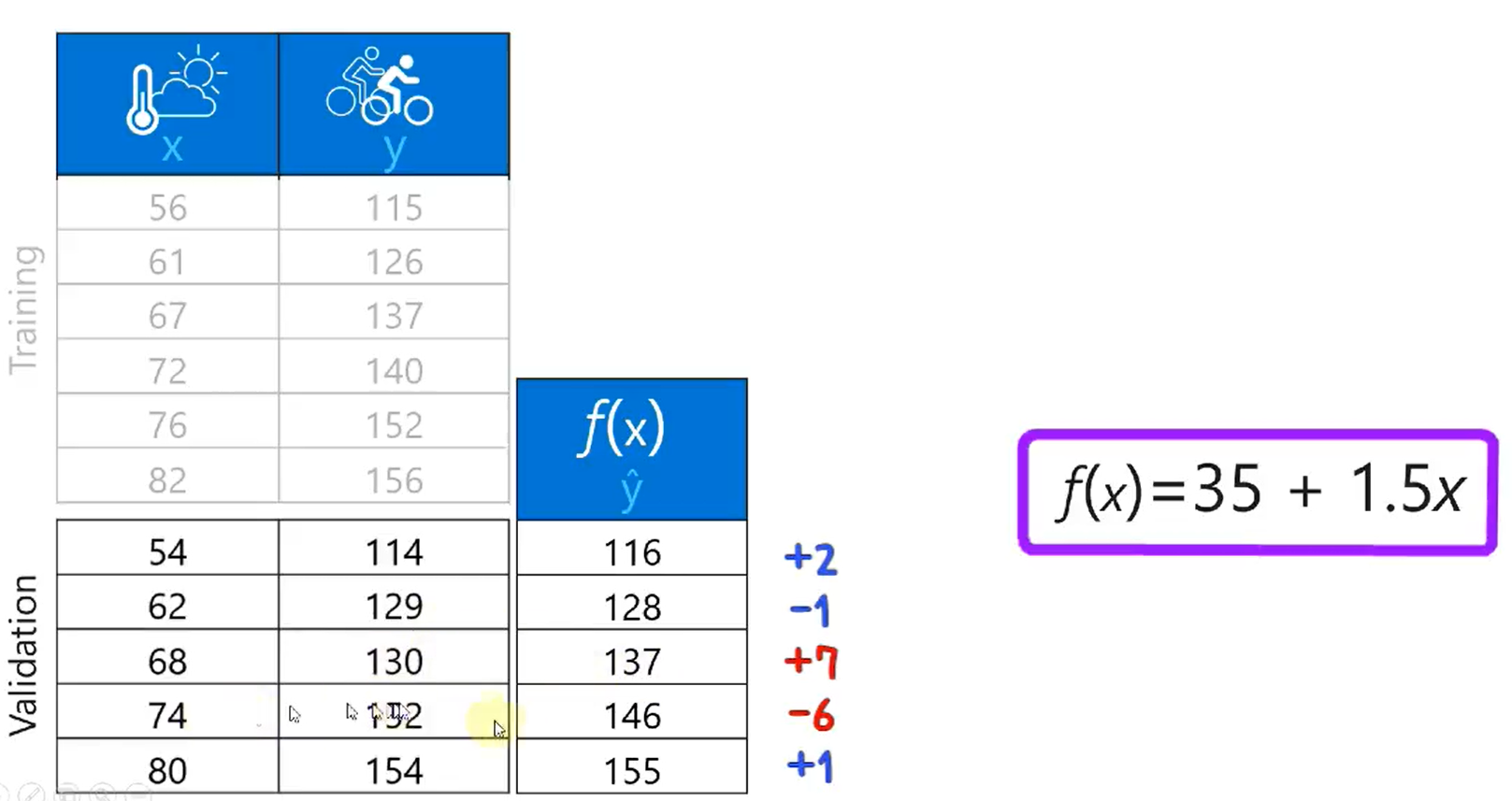

편차를 작게 하는 것이 중요!
1.3 Classification (분류)
-
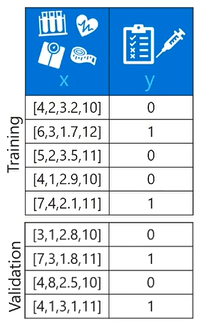

왼쪽 이미지의 당뇨병 환자 데이터를 통해 오른쪽 이미지의 그래프를 그릴 수 있습니다. 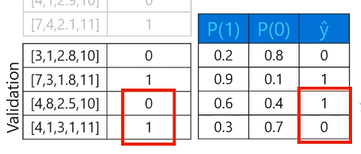
그래프로 만든 함수를 통해 Validation 값을 사용하여 예측을 진행합니다.-

True는 실제 값과 예측 값이 같을 경우를 말하고, False는 실제 값과 예측 값이 다를 경우를 말합니다. - Positive는 1일 경우 표시하고, Negative는 0일 경우 표시합니다.
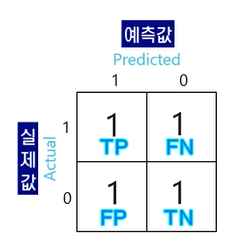
- 결론: 실제 값과 예측 값이 같고, 1이라고 예측할 경우, True Positive (TP)
실제 값과 예측 값이 같고, 0이라고 예측할 경우, True Negative (TN)
실제 값과 예측 값이 다르고, 1이라고 예측할 경우, False Positive (FP)
실제 값과 예측 값이 다르고, 0이라고 예측할 경우, False Negative (FN)
앞에는 맞췄는 지 여부 (True/False) , 뒤에는 예측한 값 (1=Positive, 0=Negative)
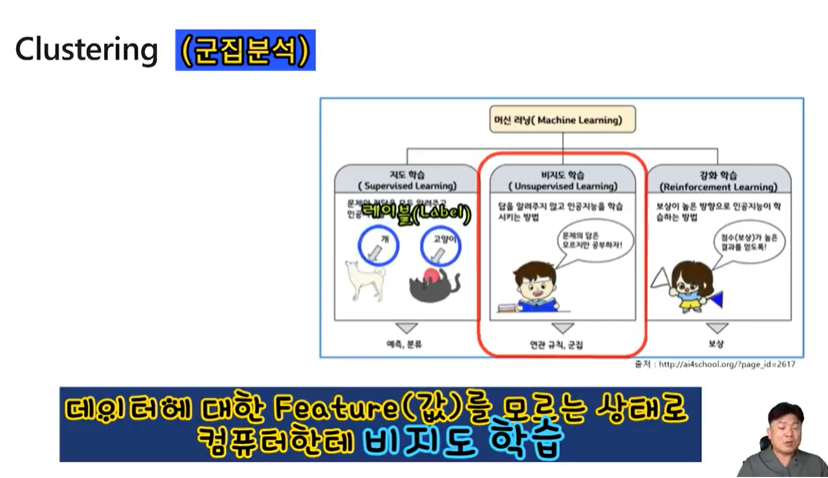
1.4 Clustering (군집분석)
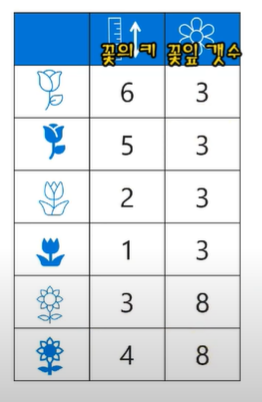
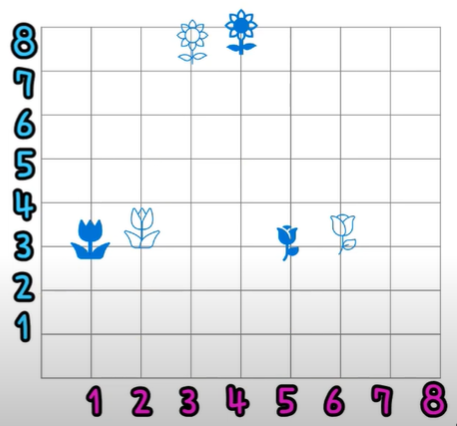
왼쪽의 꽃 별 꽃의 키와 꽃잎 갯수 데이터로 오른쪽 그래프 위에 표현할 수 있습니다.
임의의 꽃과 꽃 사이의 중심이 되는 곳에 점을 찍습니다.
꽃과 가까운 점으로 묶습니다.
그룹의 중심점을 다시 찾습니다.
꽃과 꽃 사이의 거리를 계산하고 점(평균)들로부터 가까운 꽃들끼리 묶습니다.
반복적으로 묶고 평균을 내면 데이터 안의 비슷한 패턴과 구조를 발견합니다.
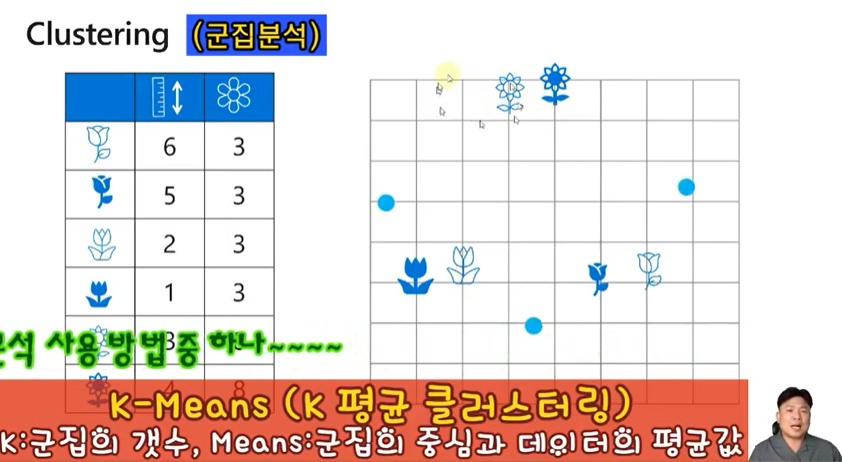
K-Means (K 평균 클러스터링)
K: 군집의 갯수, Means 군집의 중심과 데이터의 평균 값

2. Azure Machine Learning
2.1 Azure Machine Learning은 Azure Cloud 기반 머신러닝 플랫폼입니다.
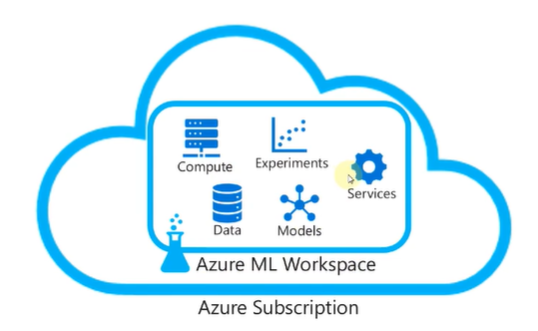
Azure 구독 내에 ML Workspace가 들어있고, Workspace 내에 컴퓨팅, 실험, 데이터, 모델링, 서비스 등이 들어있습니다.

Azure Machine Learning designer를 통해 머신러닝 파이프라인을 생성할 수 있습니다.
2.2 Automated Machine Learning
Automated Machine Learning - 데이터를 넣고 어떤 알고리즘, 어떤 모델을 선택할지 사용자가 선택했지만, 데이터를 로드, 임계값을 정해주면 인공지능이 알고리즘을 테스트하여 가장 적합한 모델을 찾아줍니다.

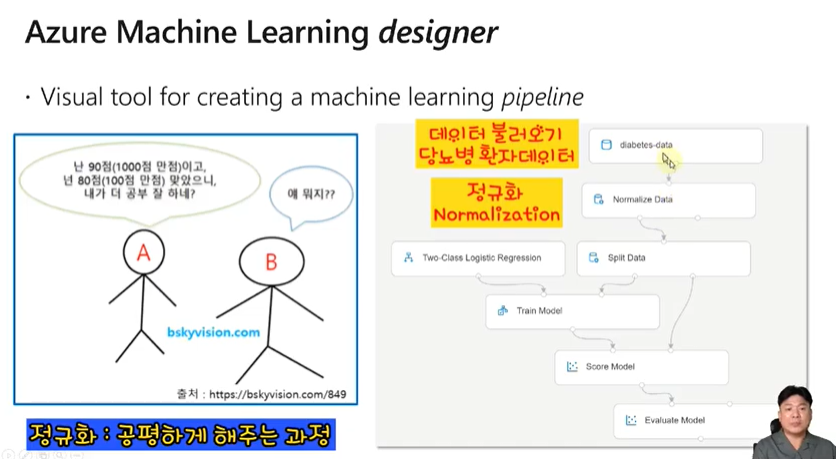
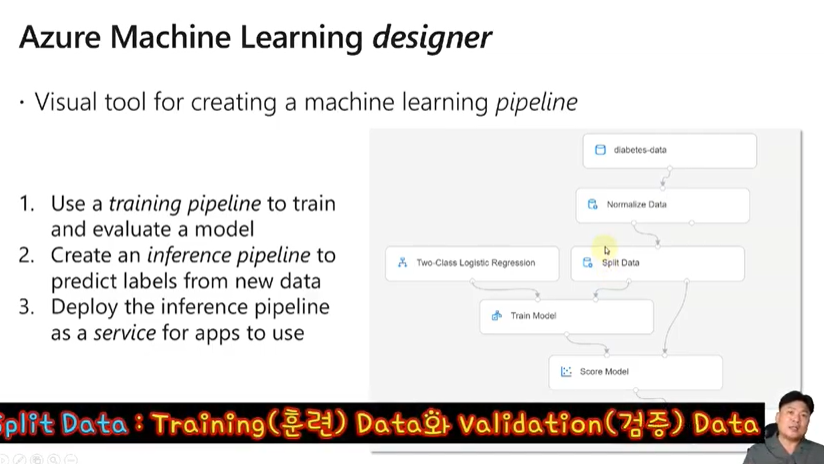
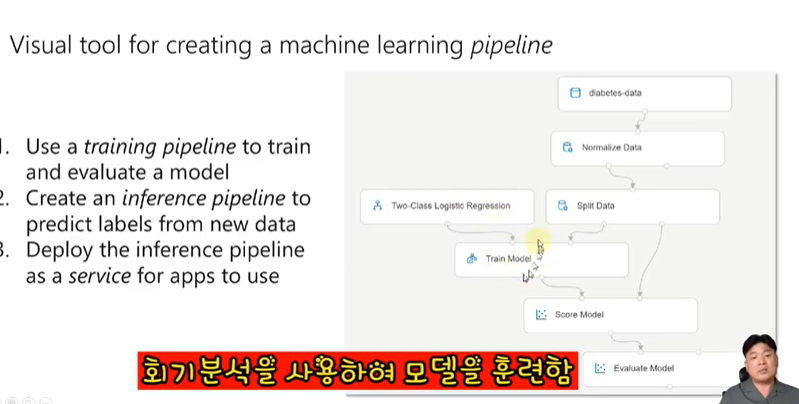
이러한 파이프라인으로 진행
